Saai talks Data Science #2
Date: 2021-03-09
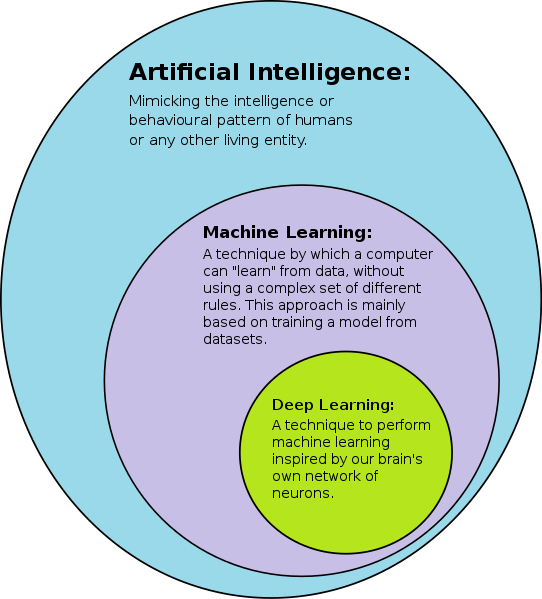
Machine Learning Introduction
What is the difference between Artificial Intelligence and Machine Learning?
Define Artificial Intelligence,
To be honest Artificial Intelligence can be defined in many ways.
This is how IBM defines Artificial Intelligence…
“Artificial intelligence refers to the ability of a computer or machine to mimic the capabilities of the human mind — learning from examples and experience, recognizing objects, understanding and responding to language, making decisions, solving problems — and combining these and other capabilities to perform functions a human might perform.” ¹
This is a definition I found on the Stanford2016 AI100 report…
“Artificial intelligence is that activity devoted to making machines intelligent, and intelligence is that quality that enables an entity to function appropriately and with foresight in its environment.” ²
According to the second definition of Artificial Intelligence, even a calculator can be considered to be intelligent, but the difference between it and the human-brain is scale, speed, degree of autonomy, and generality.
The same factors can be used to evaluate every other instance of intelligence — speech recognition software, animal brains, cruise-control systems in cars, Go-playing programs, thermostats — and to place them at some appropriate location in the spectrum.
Speech recognition software were designed for the sole purpose of recognizing speech and Go-playing programs were designed for the sole purpose of playing Go, they are not generalized and hence differ from an animal brain, which is much more complex in scale and is generalized, to perform various operations.
Calculators are significantly faster than the average human brain in calculating complex mathematical values, but lacks in degree of autonomy.
They won’t give you the output until you press the “Enter” key or the “=” key, but cruise-control systems in cars are have a greater degree of autonomy. Both come under the category of intelligence.
So piece of code that is able to mimic human intelligence can be called artificial intelligence but they all vary in the degree of intelligence they have and can be categorized in this manner.
Define Machine Learning,
Machine Learning is a subset of artificial intelligence, which involves using data in order to increase the accuracy of the results generated by the algorithm, without human intervention in the process of learning from the data.
Machine Learning algorithms optimize themselves to be better based on the data provided to them, you can note the clear line of difference here,
Machine Learning Algorithms are a far more complex algorithms, which have a higher level of autonomy compared to a calculator, though both are artificially intelligent.
They are used on a wide range of tasks such as scam filtering or computer vision.
Machine Learning can be divided into three classes :
-
Supervised Learning
-
Unsupervised Learning
-
Reinforcement Learning
Supervised Learning :
Supervised Learning refers to a class of Machine Learning the Algorithm learns to map a set of input features to a target variable.
Mostly the need for supervised learning will occur if we have a defined set of features and a target variable like in the dataset given below.
 Pima Indian Diabetes Database⁴
Pima Indian Diabetes Database⁴
Each row in the data-set represents a data sample, in our case each sample is a female at least 21 years old of Pima Indian heritage. Each Column represents a feature used to describe every person.
For example,
Patient 0 — has had 6 Pregnancies, Glucose level of 148, Blood Pressure of 72 and so on…
Our problem statement —
Given all of the features data of a female of at least 21 years old of Pima Indian Heritage except the outcome. Calculate the outcome,
Outcome of 1 represents that the patient has diabetes, and 0 suggests that the person doesn’t have diabetes.
So, we’re given the above dataset to train our machine learning model to perform this task.
We start by splitting the dataset into features-target pairs.
features = ['Pregnancies','Glucose','BloodPressure','SkinThickness','Insulin','BMI','DiabetesPedigreeFunction','Age']
target = ['Outcome']
# for Patient 0 the feature-target pair will be:
features = [6,148,72,35,0,33.6,0.627,50]
target-label = [1]
and so on for all other patients...
Our dataset consists of 5 rows, out of which we will use 3 to train the model. This data is called the training data.
We reserve the remaining 2 columns in order to test the model’s accuracy in telling us whether the patient has diabetes or not. This data is called the testing data.
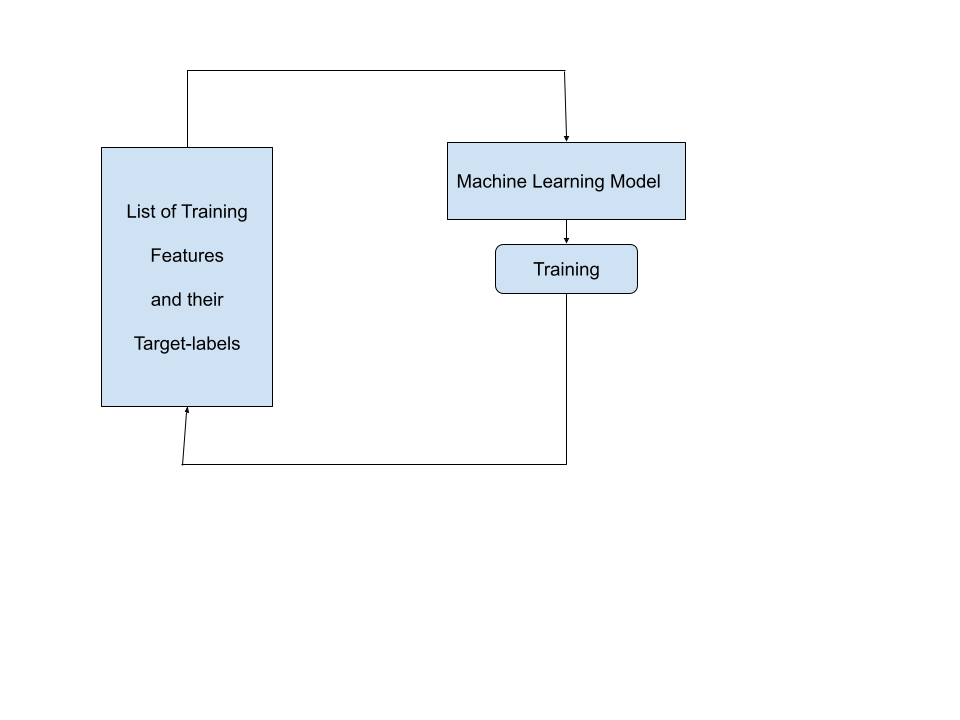
The model takes the first features-label pair.
Trains on it,and learns that for such and such values of features, the value of the target-label is…1 or 0 and so on…
and then takes the second features-label pair and does the same on this too.
In the end the model which has been exposed to 3 features label pairs knows to an extent how to map the features’ values to the value of the target.
Then on the test data, we predict results for the model and check if the model has learnt how to map the features to the target(outcome) properly or not.
If you have any feedback leave them in the comments, hope you are able to understand what I have written, if not post any doubt in the comments, I’ll try my best to answer them.
[1] https://www.ibm.com/cloud/learn/what-is-artificial-intelligence
[2]Nils J. Nilsson, *The Quest for Artificial Intelligence: A History of Ideas and Achievements *(Cambridge, UK: Cambridge University Press, 2010).
[3]*Original file: Avimanyu786 SVG version: Tukijaaliwa, CC BY-SA 4.0, via Wikimedia Commons.*
{kind=link}
[4]Smith, J.W., Everhart, J.E., Dickson, W.C., Knowler, W.C., & Johannes, R.S. (1988). Using the ADAP learning algorithm to forecast the onset of diabetes mellitus. In Proceedings of the Symposium on Computer Applications and Medical Care (pp. 261–265). IEEE Computer Society Press.